電子書籍づくり実践(本文ファイルを分割する)
今回は、ここまで作業を進めてきたxhtmlファイル(p-002.xhtml)を、しかるべきパーツごとに分割します。
書籍は通常、
- 表紙
- 本扉
- 目次
- 本文
- 奥付
といった要素により成り立っていますが、それに沿った形でファイルを分割していきます。
分割作業をする前に、まずはテンプレートのxhtmlフォルダを開き、そのうち今回使用するファイルだけを残し、それ以外削除します。
残すファイルは下記の通りです。
それではパーツごとに作業を進めていきます。
表紙
表紙用のページファイル「p-cover.xhtml」は、現在「ページ上にcover.jpg という名前の画像を目一杯の大きさに表示する」という設定がされており、その「cover.jpg」は仮の画像になっています。なのでこの仮画像を、実際に電子書籍の表紙にしたい画像に差し替えればOKです。
作業手順
始めに、テンプレートのimageフォルダ内の画像ファイルをすべて削除します。そうしたらそのフォルダに表紙で表示させたい画像を入れます。ファイル名は必ず「cover.jpg」としてください。
なお、今回つくり進めている電子書籍『こころ』用の表紙画像を用意しましたので、よろしければ下記よりダウンロードご利用ください。
https://www.dropbox.com/s/9z6ka8oi7k4aa6i/cover.jpg
{kind=link}

ダウンロードした表紙画像をお使いになる場合は、上のようになっていればOKです。
もちろん、皆さんご自身で用意した画像を表紙に使うことも可能です。その際は画像の「ピクセル数」に注意してください。
ピクセル数の確認方法
Windowsの場合
画像ファイルを右クリックし、出てきたメニューから「プロパティ」を選んでください。そうすると「cover.jpgのプロパティ」というウィンドウが表示されますので、そこで「詳細」タブをクリックして下さい。そうすると下のようなウィンドウが表示されます。

そのなかの「イメージ」という項目に「幅」と「高さ」のピクセル数が表記されていますが、その「高さ」が1500〜2500ピクセル程度であることが望ましいです。ピクセル数が少ないとぼんやりとした画像に、多過ぎると表示されないなどの問題が発生することがあります。
Macの場合
画像を右クリックして出てくるメニューから「情報を見る」をクリックすると、詳細情報という項目内に「幅」と「高さ」のピクセル数が表示されます。

デジカメで撮った画像は上記でお伝えした数値より一桁多いレベルで高ピクセルですので電子書籍で使用する際はその数値を減らす必要があります。逆に、もともとピクセル数が少ない画像データについて、その数値を増やしても画像はキレイになりません。
ピクセル数の変更方法
画像のピクセル数変更は、さまざまな画像加工ソフトで対応可能ですが、今回はWindows、Macともに最初からインストールされているソフトでの対応方法を紹介します。
Windowsの場合
「ペイント」というソフトを使います。Windowsのスタートメニュー>すべてのプログラム>アクセサリ>と進んでいくと出てきます。
「サイズ変更と傾斜」のボタンをクリックすると、同名の設定ウィンドウが出てきますのでそこに数値を入力して画像サイズを変更します。

Macの場合
「プレビュー」というソフトを使います。初期設定でDockに設定されています。

まず画像ファイルをプレビューで開きます(プレビューのアイコンにドラッグ&ドロップすると開きます)。画像が開いたら、メニューバーの「ツール」をクリックし、そのメニューにある「サイズを調整」とクリックします。そうすると設定ウィンドウが出てきますのでそこに数値を入力して画像サイズを変更します。

電子書籍づくりに限らず、画像データのピクセル数を変更することは、パソコン仕事をしているとままあります。これを機会にそのやり方を押さえておきましょう。
本扉
p-002.xhtmlをエディタで開いていただき、ファイルの先頭の方を表示すると、
<p>こころ</p>
<p>夏目漱石</p>
という2行が見えると思います。
これが今回本扉で表示させたい内容です。
作業手順
「作品名」と「著者名」の2行を、本文ファイル(p-002.xhtml)から本扉ファイル(p-titlepage.xhtml)へ移動するのですが、その手段としてこの2行を「切り取り」ます*1。また併せて、その下にある【テキスト内に現れる記号に付いて】という説明書き(上下に破線のある部分)を削除します。

次に「p-titlepage.xhtml」をエディタで開いて、切り取った内容を下記の通りに貼付けます。
また同時に
<div class="main">
となっている行を
<div class="vrtl block-align-center" style="height:100%;">
に差し替えてください。下のようになればOKです。

問題なければp-titlepage.xhtml、p-002.xhtmlとも上書き保存してください。次にp-titlepage.xhtmlをブラウザで開きます。

このように見えればOKです。先ほどdivタグを変更しましたが、これによって本扉ページのセンター位置に縦書きで文字が配置されるようになりました。
奥付
目次と本文はちょっと後回しにして、先に「奥付」をつくります。
作業手順
p-002.xhtmlをエディタで開いていただき、ファイルの終わりの方を表示します。

上の画像の通り
底本:「こころ」〜
から
〜ボランティアの皆さんです。</p>
までをp-002.xhtmlから切り取ります。
次に「p-colophon.xhtml」をエディタで開いて、先ほど切り取った内容を下記の青くなっている箇所に貼付けます。

貼付けたらp-colophon.xhtml、p-002.xhtmlとも上書き保存してください。次にp-colophon.xhtmlをブラウザで開きます。

このように見えればOKです。ちなみに奥付はあえて横書きになるように設定してあります。
本文
書籍の本文は、一般的に「章」「節」「見出し」といった階層構造になっていることを皆さんご存知かと思うのですが、電子書籍の場合、いずれかの階層でファイルを分割するのが常となっています。
現在このブログでは夏目漱石の『こころ』の電子書籍を作り進めていますが、この小説の構造を例に見ていきましょう。
下の「p-toc.xhtml」からもわかる通り、この小説は「上」「中」「下」の章に別れており、その中がさらに漢数字で節に別れています。

今回、本文ファイルは「章ごと」で分けることとしますので、本文ファイルは3つになります。
作業手順
まず「p-002.xhtml」を二つ複製してください。

増えた2つのファイルを、それぞれ
にファイル名を変更してください。

このようになればOKです。
この3ファイルはファイルネームこそ異なりますが、現時点では内容はすべて同じ(1章から3章まですべて含まれる本文データ)です。ここから各ファイルごとに「必要な内容」だけを残し、それ以外を削除します。
要は
p-001.xhtml → 1章(「上」)だけ残す=2章と3章部分を削除。
p-002.xhtml → 2章(「中」)だけ残す=1章と3章部分を削除。
p-003.xhtml → 3章(「下」)だけ残す=1章と2章部分を削除。
となればOK、ということになります。
各章とも、始まりは「h1タグの行」からになります。また章と章の間(上と中の間・中と下の間)には
[#改ページ]
という章の区切りとなるマークが入っているので、それらをエディタの検索機能で探しながら、指定されたセンテンスだけを残すように作業してみてください。
また、3ファイルとも「(x)htmlのファイルにお決まりで記述する文言」が入っている必要があるので、誤ってそれまで削除してしまわないよう注意してください。

目次と本文のリンク
最後に目次ファイル「navigation-documents.xhtml」「p-toc.xhtml」を調整します。
作業手順
navigation-documents.xhtmlをテキストエディタで開きます。
全ての行について、その記述には一定の法則があり、その意味は下記の通りとなります。

ここには目次項目(青いアンダーライン部分)から、本文のどこ(赤のアンダーライン)にジャンプするのかが記述されています。そしてジャンプ先の「id」については、以前の作業で連番が振られているから良いのですが、「ファイル名」の部分は現状のままだと問題があります。なぜならそのファイル名を表す部分がすべて「p-000.xhtml」という仮のファイル名のままになっているからです。なのでこれから、この部分を実情に沿ったファイル名に変更していきます。
現在、電子書籍の作成を進めている『こころ』では、
本文は
第一章(「上」と呼ばれるセンテンス)→p-001.xhtml
第二章(「中」と呼ばれるセンテンス)→p-002.xhtml
第三章(「下」と呼ばれるセンテンス)→p-003.xhtml
の3ファイルになるので、目次内のファイル名もそれに対応するように直します。
その際は検索置換をうまく使って作業を省力化しましょう。

置換する際には、選択した範囲のみに置換が掛かるよう設定してから作業します。

論理目次のリンクの修正が終わったら、本文目次も同じ要領で作業します。やるとこは同じです(リンク内の「p-000.xhtml」に対応する本文ファイル名に直します)。
今日のまとめ
EPUBの構造。今回はその役割りごとにページファイル(.xhtml)を分割しました。
その内訳は
- 表紙
- 本扉
- 目次
- 本文×3ファイル
- 奥付
となりました。
また分割によりできた本文のファイル名を「論理目次」「本文目次」のそれぞれに反映させます。
次回は
電子書籍づくり実践(書誌情報を書く)についてお話します。
*1:コピーでなく切り取り。ショートカットは「ctrl+X」となります。
電子書籍づくり実践(EPUBの構造 目次を作る2)
前回は、目次とリンクさせるために必要な「id」を、本文の見出し側に付与しました。今回はそれとリンクする目次自体のデータを作りながら、その仕組みを学びます。
つくる目次ファイルは“二つ”
目次として機能するファイルを二つ作ります。なおこのファイルはここまでつくり進めて来た、EPUBテンプレート*1内に既に存在しますので、それに追記する形で作業を進めていきます。
下の構造図で、赤丸のついた2ファイルです。
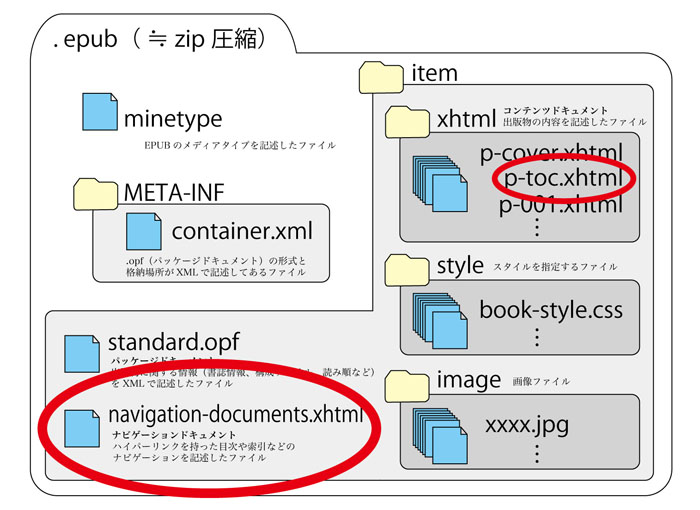
navigation-documents.xhtmlは論理目次
構造図の左下にある「navigation-documents.xhtml」は論理目次といい、リーダー側の仕組みから呼び出される目次です。

p-toc.xhtmlは本文目次
構造図の右上にある「p-toc.xhtml」は本文目次といい、本文ページファイルとして存在する目次で、本のページをめくっていくと出てくる目次です。

なおこのように目次情報をふたつ作るには理由があり、それはリーディングシステム*2によっては「どちらか片方の目次の仕組みにしか対応していない」場合があるためです。
目次ファイルの作り方
それでは目次ファイルの作り方を説明します。
全体の流れてとしては、まずは本文の内容から見出し項目(=目次項目)だけを抜き残します(正規表現の検索置換を使う)。次に目次に必要な情報を新たに付加します。また、つくる順番としては、まず論理目次をつくり、そこから本文目次をつくり出します。
本文ファイル→論理目次の書き出し
まずは論理目次をつくります。
本文ファイル自体、これはこれとして必要なデータなので、まずは「p-002.xhtml」をコピペなどして複製します(複製したファイルはどこに置いてもOKです)。ファイル名は「mokuji.xhtml」としておきましょう。
次に「mokuji.xhtml」をエディタで開き、下記の3組の検索置換を掛けていきます。
ねらい:pタグのついた文章の削除(=見出し部分だけを残す)
- 検索
- <p>(.+?)</p>
- 置換
- 空欄
ねらい:残ったものからhタグを外し、idを生かしつつ、liタグに付け替えます
- 検索
- <h[0-9] .+?id="(toc-[0-9][0-9][0-9][0-9])">(.+?)</h[0-9]>
ねらい:不要な改行を削除
- 検索
- ^\n ※emeditorの場合
^\r ※miの場合
- 置換
- 空欄
検索置換が完了するとエディタでは下のように見えます。

できたら上書き保存し、次にこの内容を「すべて選択」して「コピー」します。
続いてテンプレートのフォルダ内にある「navigation-documents.xhtml」をエディタで開きます。
開いたら
<ol>
と
</ol>
の間に先ほどコピーしたデータを貼付けます。

貼り付けが出来たら上書き保存し、今度はブラウザで「navigation-documents.xhtml」を開いてみます。

このように表示されていればOKです。
論理目次→本文目次の書き出し
続いて本文目次のファイルを作ります。
先ほどつくった「mokuji.xhtml」を複製し、ファイルネームを「honbun-mokuji.xhtml」とします(この複製ファイルはどこに置いてもOKです)。
これをエディタで開き、下記の2組の検索置換を掛けていきます。
ねらい:不要な記述を削除します。
- 検索
- xhtml/
- 置換
- 空欄
ねらい:liタグをpタグに変更します。
- 検索
- li>
- 置換
- p>
検索置換が完了するとエディタでは下のように見えます。

できたら上書き保存し、次にこの内容を「すべて選択」して「コピー」します
続いてテンプレートのフォルダ内にある「xhtmlフォルダ」を開き、その中の「p-toc.xhtml」をエディタで開きます。
開いたら
<p><br /></p>
と
</div>
の間に先ほどコピーしたデータを貼付けます。

貼り付けが出来たら上書き保存し、今度はブラウザで「p-toc.xhtml」を開いてみます。

このように表示されていればOKです。
なお作業後「mokuji.xhtml」と「honbun-mokuji.xhtml」は不要なので削除してください。
今日のまとめ
EPUBの構造。今回は目次ファイルをつくりました。
目次ファイルは
のふたつが必要。
またその作成には正規表現による検索置換を使い、作業を省力化します。
次回は
電子書籍づくり実践(EPUBの構造 本文ファイルを分割する)についてお話します。
*1:日本電子書籍出版社協会電書協EPUB 3 制作ガイド。下記よりダウンロードできます。http://www.ebpaj.jp/guide.html
その中にある「book-template.epub」というファイルの拡張子を.zipに変更し、解凍すると上図の構造を持ったフォルダが作られます
電子書籍づくり実践(EPUBの構造 目次を作る1)
今回から2回に渡り、電子書籍の「目次」の仕組みをお伝えします。実際に目次データ作りながら、その構造を理解していきましょう。
本文見出しにidを振る
前回の「スタイル」に続き、今回も本文の見出しに対して「仕掛け」をします。
それは「idを振る」ことです。
この「id」が何なのかは、作業を進めると自然と理解していただけると思いますで、ここで詳しく説明はしませんが、簡単に言えば id = 「本文見出し」と「目次」を関連づけるのに必要なものです。
それでは作業を進めていきましょう。
いままで作り進めてきたEPUBテンプレートの「p-002.xhtml」をエディタで開いていただき、まずは下記の正規表現で検索置換を掛けます。
- 検索
- <h([0-9].+?)>
- 置換
- <h$1 id="toc-X">
この検索置換により、h1、h2 全ての見出しの開始タグに「id="toc-X"」が付与されます。

上と同じように置換されているのが確認できたら、上書き保存してください。
続けて id="toc-X"の「X」の部分を、連番(0001、0002、0003…)にしていくのですが、ひとつひとつ入力し直すのはしんどいので、ツールを使って作業をします。なお、作業に使うツールはWindowsとMacで別となります。
連番を振る作業(Windowsの場合)
「テキスト内の任意の文字を連番に変換するソフト」を使って省力化します。
Replace Tool(フリーウェア)
http://www.vector.co.jp/soft/dl/winnt/util/se478077.html
上記よりzipファイルをダウンロードし、解凍します。
解凍後、フォルダ内の「ReplaceTool.exe」というファイルをダブルクリックして起動すると下記のようなウィンドウが開きます。

次に「p-002.xhtml」の「エンコード」を変更します。
補足
実は今回連番付与に使う「ReplaceTool」というソフトが「UTF-8(BOM無し)」に対応していません。*1
ちょっと手間なのですが一度「UTF-8(BOM付き)」に変更してから連番を付与し、作業完了後「UTF-8(BOM無し)」に再度戻す、という作業が必要になります。*2
「p-002.xhtml」をEmEditorで開き、メニューバーの「ファイル」から「名前を付けて保存」を選択。ファイル名は変えず、エンコードを「UTF-8(BOM無し)」から「UTF-8(BOM付き)」にして上書き保存します。
エンコードを変更したら「p-002.xhtml」を「ReplaceTool」の右の枠内にドラッグ&ドロップします。

次に連番の検索置換設定をします。
検索文字列:toc-X
置換後の文字列:toc-
連番をつける:チェック入れる
開始番号:1
桁数:4

このようになればOKです。
問題なければ「置換」ボタンを押します。

無事連番が振られました。
連番が間違いなく振られたのを確認できたら、文字のエンコードを「UTF-8(BOM付き)」から「UTF-8(BOM無し)」に変更し(元に戻し)、上書き保存します。
連番を振る作業(Macの場合)
次にMacでの連番の振り方を説明します。
Macでは「ドロップレット」という仕組みを使います。
下記よりダウンロード下さい。
https://www.dropbox.com/sh/i2jnvrmaaj2r43g/-3cHOXQ6H_
「renban.app」というファイルがダウンロードできたら、そのアイコンの上に「p-002.xhtml」をドラッグ&ドロップします。

これで完了です。「p-002.xhtml」をエディタで開くと指定した場所が連番に変っているのが確認できます。
「ドロップレット」とは、それ自体に「連番をどう振るか」の命令が組み込まれており、またそれを実行する仕組みも組み込まれているファイルです。
今日のまとめ
EPUBの構造。今回は本文の見出しにidを振りました。
idは「本文見出し」と「目次」を関連づけるために必要。
idの付与方法
ともに作業の省力化が目的。
次回は
電子書籍づくり実践(EPUBの構造 目次を作る2)についてお話します。
電子書籍づくり実践(EPUBの構造 xhtmlとcss)
このブログでは、前々回のエントリまで数回に渡り
- 文章にタグ付けをし
- 用意したEPUBテンプレートにコピペし
- その内容をブラウザで表示確認をする
という作業をして来ました。
今回はそこで使った「テンプレート」を通して、EPUBの構造を学んでおきましょう。「構造」などというと難しく聞こえますが、押さえておくのは下記の点だけです。
.epubとは
- 必要なファイル類を
- 定められたフォルダ構成に従って配置し、
- 圧縮したもの。
以上です。
その構造を絵的に表すと下記の通りになります。

テンプレートとして、既にこの構造になっているデータ*1があるわけですから、特にこの構造を覚えるたりとか、イチから自分で作ったりする必要もありません。現時点で押さえておきたいのは
- テンプレートのどこに手を入れる必要があるか?
- その部分はどんな働きをしているのか?
という点だけです。
それではEPUBを構成する「中身」を見ていきましょう。
ここからは書かれる文字を追うだけでなく、前々回使ったテンプレートを開いて、内容を対比させながら読み進めると理解しやすいと思います。
xhtmlファイルは「本の中身」(xhtmlフォルダ)
電子書籍づくりで一番たくさんの手を入れるのが、xhtmlフォルダの「ページファイル(拡張子.xhtml)」です。

このファイルに、電子書籍で表示させたい内容を書き込みます。書き込むルールはhtmlが進化したxhtmlという記述言語です。*2
cssで「見た目」をコントロールする(styleフォルダ)
xhtmlフォルダと同じ階層に「style」という名前のフォルダあります。

このフォルダには、拡張子が「.css」となっているファイルが複数入っています。「css」とは、フォルダ名の通り、「スタイル」をコントロールするためのファイルです。といっても「?」だと思うので、それでは実際に「コントロール」してみましょう。
スタイルをコントロール「する側」の記述
前々回に使用した「book-template - コピー」フォルダを用意してください。その中にある「styleフォルダ」を開き、その中の「book-style.css」をエディタで開きます。開いたら「tobira-midashi」で検索を掛けます。
そうすると該当箇所として下記が表示されます。

ここに下記の内容を追記します。
.vrtl .tobira-midashi {
と
}
の間に
font-size:3em;
.vrtl .oo-midashi {
と
}
の間に
font-size:2em;

このようになります。
問題なければ上書き保存してください。
それでは、いま記述した内容が何なのか説明します。
font-size
とは読んで字の通り「文字(フォント)のサイズ」を指定しています。
em
とは文字サイズの単位で、基本サイズを「1em」とし、数値が大きくなるほど文字サイズも大きくなります。
上のように記述することにより
- スタイル名*3
- tobira-midashi
- 指示内容
- 文字サイズを3emに
- スタイル名
- oo-midashi
- 指示内容
- 文字サイズを2emに
というスタイルが、CSSのファイルに登録されたことになります。
次にこのスタイルの指示を「受ける側」の設定をします。
今回は
- 「tobira-midashi」のスタイルを反映させるのはh1の文章
- 「oo-midashi」のスタイルを反映させるのはh2の文章
とします。
スタイルをコントロール「される側」の記述
xhtmlフォルダ内の「p-002.xhtml」をエディタで開き、下記の検索置換を2回に分けて掛けます。
- 検索
- <h1>
- 置換
- <h1 class="tobira-midashi">
- 検索
- <h2>
- 置換
- <h2 class="oo-midashi">
下のようになればOKです。
問題なければ上書き保存してください。

cssに記述したスタイルを反映させるには、上のように反映したい箇所の開始タグに「class="スタイル名"」と記述をします。
それでは文字サイズの指定がされた「p-002.xhtmlの見出し(h1、h2)」がどのように見えるか確認してみましょう。
p-002.xhtmをブラウザで開きます。

見出しの文字サイズが大きくなっていることが確認できます。またh1、h2でそのサイズが異なっている(h1のほうがh2より大きい)のも確認できます。
これが「CSSに登録されたスタイルが、xhtml側のしかるべき場所(今回の場合h1とh2)に反映させた状態」です。
CSSについての知識
今回、話しの中心となった「CSS」ですが、説明としてはこれから電子書籍をつくり進めるうえで、必要最低限の内容になっています。
こちらもHTML同様、知識の積み増しをした方がより楽しく電子書籍を制作することができますし、またweb制作にも深く関係している技術なので、そちらの知識習得も兼ねて学び進めるのも良いと思います。
初心者向けの解説サイトとしては
やさしいホームページ入門:CSS入門
http://www.ink.or.jp/~bigblock/css/index.html
が解りやすくておすすめです。
また「CSS 入門」などのキーワードでGoogle検索して、自分に合った学習サイトを探してみるのも良いかもしれません。
そうしてCSSへの理解を深められたら、現在使っているEPUBテンプレートと一緒にダウンロードしたデータの中にある「CSS機能一覧.pdf」に目を通してみてください。これはテンプレート内で「既に設定されているスタイルの一覧」で、今後電子書籍づくりを進める際にとても役に立ちます。
今日のまとめ
EPUBの構造。今回は
の役割について説明しました。
その関係性は
となります。
次回は
電子書籍づくり実践(EPUBの構造 目次を作る1)についてお話します。
*1:日本電子書籍出版社協会電書協EPUB 3 制作ガイド。下記よりダウンロードできます。http://www.ebpaj.jp/guide.html
その中にある「book-template.epub」というファイルの拡張子を.zipに変更し、解凍すると上図の構造を持ったフォルダが作られます
*2:ここでhtmlとxhtmlの違いは意識しなくてもOKです。同じようなものと理解しておいてください。
*3:この部分を正式には「class名」といいます
電子書籍づくり実践(トラブル対応)
このブログでここまで進めてきた「電子書籍のデータの作成」は、基本「書いてある通りに作業すればOK」となるよう、その内容をお伝えしてきました。
ただ皆さんのなかには
「書いある通り作業したのにうまくいかない」
という状況の方もいるかもしれません。
なので今回は、その原因として私自身が思い当たることをお伝えしようと思います。また併せて、「うまくいかない」という状況に陥らないためのコツもお伝えします。
トラブル1:検索置換が掛からない
検索置換が上手くいかないときは下記の点を確認してみましょう。
正規表現のチェックは入っているか?
これを結構うっかり忘れることがあります。多くのエディタは一回そのソフトを終了してしまうと正規表現のチェックが外れてしまう仕様のものが多いので要注意です。

使っているエディタに適した正規表現を入力しているか?
ブログでお伝えしている正規表現の中には、エディタによってその記述方法の異なる場合があります。ご自身がご利用のエディタに対応した正規表現を使用しているか、確認してみましょう。
なおこのブログで使用を想定しているエディタ( EmEditor と mi )については、こちらで正規表現の動作確認は行っていますが、それ以外のエディタについては微妙な記述ルールの違いに正規表現が正しく効かないケースがあります。
目に見えない誤入力はないか?
検索置換のワードを、エディタの検索置換欄に貼付ける際、不要な「スペース」や「改行」まで、誤ってコピペしてしまうケースがあります。ぱっとみは何も見えないので発見しにくいのですが、検索置換が動かないときは「見えないに何かが混ざっている」可能性があります。

次に検索置換でつまずかないためのコツをいくつか挙げてみます。
コピペを使う
手入力は誤入力のもとです。マークアップのタイピングに慣れている人以外は短い検索置換ワードでもブログ内からコピペした方が無難です。
コピー箇所の「選択」を厳密に
検索ワードや置換ワードをコピーする際、「余計な一文字を含めてしまう」「必要な一文字を選択しはぐってしまう」ということがよくあります。マウスで文字を選択する動作と、マウスで必要箇所をなぞった後の「ちゃんと選択できているか」の確認に、少しだけ時間と集中力を割くと検索置換のトラブルは減ります。
トラブル2:ブラウザで開くとエラーが出る。
タグ付け(マークアップ)のルールが守られていないと、下のような英語のエラーメッセージが出ます。 
エラーメッセージの内容は下記の通りです。
This page contains the following errors:
error on line 35 at column 682: Opening and ending tag mismatch: div line 0 and p
Below is a rendering of the page up to the first error.
それではこのメーッセージを手掛かりに、問題箇所を探してみましょう。
このメッセージから
- 35行目に問題がある
- 開始タグと終了タグがミスマッチである
を読み取ることが出来ると思います。
エラーの出ているファイルをエディタで開き、35行目を確認してみると…

開始タグに問題があることがわかりました。
このメッセージ、実際に問題のある行とは異なる行数を提示することもあるので100%信用は出来ないのですが、指定された行にエラーが見つからない場合は、その行の「前後」も含めて探すとエラーの原因はだいたい見つけられます。
このように英語ではありますが「どこが間違っているのか」をエラーメッセージは教えてくれるので、これを活かしてエラーを潰していきましょう。また、この作業をやりやすくするため、エディタの「行番号」は表示する設定にしておきましょう。
EmEditorの場合
メニューバーの「ツール」から「すべての設定のプロパティ」を選択。そうすると下のような設定ウィンドウが出るので「行番号を表示」にチェックを入れます。

行番号の表示のさせ方は、ほかのエディタでも設定メニューなどに含まれていることが多いようです。
次にマークアップでエラーを出さないためのコツをいくつか挙げてみます。
手入力を減らす
手入力による誤入力を減らす意味で、なるべく正規表現の検索置換やコピペを使って作業しましょう。(特に慣れるまでは)
バックアップを取りながら作業する
自分も経験があるのですが、慣れていないと「どうしてもエラーが消えない」という状況になることもあり得ます。その場合「少し前の状態に戻って作業する」という選択をした方が、結果として作業時間が短縮できる場合があります。そのためにも作業の要所要所でのバックアップを取ることをお薦めします。
方法としては現在作業しているファイルの後ろに「_001」など通し番号を振って別の場所に保存し、作業が一段落するまで定期的に「_002」「_003」…とバックアップしていくやり方です。ただバックアップファイル自体の管理をきちんとしないと何が新しいのか古いのかわからなくなり混乱するので注意が必要です。
続いてエラーの解決方法について考えてみます。
エラー箇所の探し方
エラーメッセージの情報だけではエラー箇所が見つけられない場合があります。かといって長い文章の頭から目視でエラーを探すのも効率的ではありません。そんな場合のエラーの探し方をお伝えします。
例<1章から3章まである小説でエラーが出ている場合>
作業開始前に現状を上書き保存します。
1章だけ削除して上書き保存
ブラウザで開く→『エラー出る?出ない?』
エラーが出なくなったなら=エラーの原因は1章の中にある
エラーがまだ出るなら
2章も削除して上書き保存
ブラウザで開く→『エラー出る?出ない?』
エラーが出なくなったなら=エラーの原因は2章の中にある
エラーがまだ出るなら=エラーの原因は3章の中にある
エラーがどの章にあるのかわかったら、キーボードショットカットの「ctrl+Z」でファイルを作業開始前に上書き保存したところまで戻し、続けて問題のある章の中を同じ要領で絞り込みます。
この作業で注意が必要なのは下記の点です。
作業の途中で「ファイルを閉じない」
テキストエディタは「保存」を掛けた後でも、そのファイルが開いた時点までは「ctrl+Z」で戻ることができます。しかしファイル自体を閉じてしまうと、再度開いたときには「閉じたときの状態」でしか内容は表示されません。エディタで手を入れたファイルをブラウザで開く際、ついついエディタのウィンドウを閉じたくなるのですが、それはしないで下さい。
変なところで切らない
開始タグと終了タグが、場合によっては非常に遠い場所に存在する場合もあるので、それらが上記の作業でバラバラにならないよう注意が必要です(そうしないと新たなエラーが増えてしてしまいます)。どの開始タグがどの終了タグと紐付いているか、確認しながら作業しましょう。
なんのことはないアナログな方法ですが、目視で探すよりは効率的です。またこのようなエラー対応作業が、htmlの構造を体感的に理解するのに役立ったりもするので、エラーが出ても辛抱強く対応すると良いと思います。(もちろん最初からエラーが出ないのが一番良いのですが…)
今日のまとめ
よくあるトラブルの内容
それぞれに対して
- その原因
- 起こらないようにするための工夫
- トラブルになったときの対応方法について
考えました。
次回は
電子書籍づくり実践(EPUBの構造 xhtmlとcss)についてお話します。
電子書籍づくり実践(表示確認。その方法)
それでは前回マークアップした内容をブラウザで表示してみましょう。
以前も何度かやったとおり、マークアップした文章をブラウザで表示するには、それを「入れ物」に入れる必要があります。
「EPUBテンプレート」という入れ物
今回使う「入れ物」は下記よりダウンロードします。
日本電子書籍出版社協会電書協EPUB 3 制作ガイド
http://ebpaj.jp/counsel/guide

上のウェブページから「電書協 EPUB 3 制作ガイド ver.1.1.3 2015年1月1日版」というzipファイル(ファイル名はebpaj_epub3guide_ver1.1.3-150101.zip)をダウンロードし、解凍*1して下さい。そして解凍して出来る「ebpaj_epub3guide_ver1.1.3_150101」というフォルダ内の「ver.1.1.3付録」フォルダ内に「book-template.epub」という名前のファイルがあるのを確認してください。これを「入れ物」として使います。
拡張子を見てお気づきの方もいるかと思いますが、これは電子書籍のファイル(EPUBファイル)です。このテンプレートは、電書協(日本電子書籍出版社協会 http://ebpaj.jp/)という電子書籍の業界団体がその構造の標準化を目的に作ったもので、プロの制作現場でもこれを「下敷き」にして電子書籍を作っているところが多いです。またデータの使用はフリーです。
名前の通り、このファイルは「テンプレート(ひな形)」ですので、特に大した内容は入っていません(あくまでも“入れ物”です)。これからこのファイルに電子書籍として表示させたい内容を入れていきます。
.epubとは実はファイルの集合体
それではどうやってこの.epubファイルの中に、マークアップした文章を入れるのか?その手順をこれから説明します。
まず「book-template.epub」を複製し、テンプレートファイルをもう一つ用意します(先ほど用意したファイル自体を書き換えてしまうと、今度また電子書籍をつくるときに再度ダウンロードしなければいけないので)。作り方は下記の通りです。

「ファイル自体をその場でコピペ」すればOKです。またキーボードショットカットでも対応可能です。
上記の通り作業すると「book-template - コピー.epub」という複製ファイルが出来ますので、次にその「拡張子」を「.epub」から「.zip」に変更します(途中アラート(=警告)が出ますが気にせず「はい」をクリックしてOKです)。
拡張子の変更によって出来た「book-template - コピー.zip」を解凍してください。

解凍するとzipファイルと同じ名前の「book-template - コピー」というフォルダが作られます。
そのフォルダ内を、item>xhtml>の順でフォルダを開いていくと、拡張子が「.xhtml」のファイルが複数見えてくると思います。
次にこの中の「p-002.xhtml」のファイルをテキストエディタで開きます。

エディタで開いたら
「<h1 class="oo-midashi"〜」で始まる行から
「<p> この文章はサンプルです。〜」で始まる行まで
削除します。

削除したら、その替わりに皆さんがここまででマークアップしてきた文章をコピペで貼付けてみましょう。
出来たら上書き保存して、この「p-002.xhtml」をブラウザで開いて表示の確認をしてみましょう。
ブラウザで表示確認してみる

こんな感じになっていればOKです。
なおWindowsのChromeの場合、ブラウザの初期設定のままだと縦書きの文字間隔が正常に表示されないので、下記の通りフォントの設定を変更してみてください。




今日のまとめ
マークアップした文章をブラウザで表示確認する。
その方法:「EPUBテンプレート」を使う
次回は
電子書籍づくり実践(トラブル対応)についてお話します。
電子書籍づくり実践(マークアップ)
前回の作業で電子書籍に使う「素材」の用意ができましたので、いよいよ今回からは実際につくる作業に入ります。
前々回までにお話しした通り、htmlのルールに沿って、正規表現を用いて効率的にマークアップ(タグ付け)しながら、「本(電子書籍)」を作っていきます。なお特に指示がない限り、検索置換は「すべてを置換」ボタンで実行してください。
本文タグ
まずは本文にpタグをつけています。使用する正規表現は下記の通りです。
- 検索
- (.+)
- 置換
- <p>$1</p>
文章内にはこの後説明する「見出し」など、本文以外の要素もありますが、とりあえずすべてに対して「pタグ」をつけてしまいます。

見出しタグ
小説などの文章は、多くの場合「見出し」という要素を持っています。

青空文庫からダウンロードした『こころ』のテキストデータにも、見出しがあることが確認できます。
電子書籍においても紙の本同様、見出しは本文と別扱いにします。そのため見出しには「見出し用のタグ」をつけることになります。
見出し用のタグを付与するための正規表現は下記の通りです。
大見出し用
- 検索
- <p>[#2字下げ](.+)[(.+)は大見出し]</p>
- 置換
- <h1>$1</h1>
中見出し用
- 検索
- <p>[#5字下げ](.+)[(.+)は中見出し]</p>
- 置換
- <h2>$1</h2>
「大見出しへのタグ付け」と「中見出しへのタグ付け」、2回に分けて作業します。これらの検索置換を掛け終わると、文章内すべての見出しに「見出しタグ」が付きます。

ちなみにこの「hタグ」の「h」は Heading(見出し)の略です。また「h1」から「h6」までのレベルがあり、「h1」が一番大きな見出し、「h6」が一番小さな見出しになります。
縦中横タグ
次に縦中横のタグをつけていきます。本好きな方ならご存知の方も多いかと思いますが、縦中横とは「縦書き文章の中の(英)数字を正立させる」ことを指します。横書きの本をつくる場合、このタグは不要です。

このように表示するには下記の様なタグ付けをしていきます。
- 一桁
- …都と道が<span class="tcy">1</span>と、…
- 二桁
- …県が<span class="tcy">43</span>となる。
- 三桁
- …以前は人口
<span class="tcy">1</span>
<span class="tcy">0</span>
<span class="tcy">0</span>万人と…
このように<span class="tcy">と</span>というタグで英数字を囲むと上記の「設定後」ように「正立」するのですが、ルールとして2桁の数字のみ「並べて正立」、それ以外の桁数は一文字ずつ正立させることが多いです。また数字だけでなく英字にも縦中横を設定する場合がありますが、こちらはルールが一定でないので逐次対応とします。

それでは正規表現を使い縦中横のタグを付けていきましょう。
なお縦中横タグを付与するために使う正規表現なのですが、実は「EmEditor」と「mi」で、その記述方法が異なります。それぞれでうまく検索置換できる正規表現をエディタごとに記述しますので、お使いのエディタ用の正規表現で作業を進めてください。またタグ付けは「桁数ごと」に行います。
EmEditorの場合
1桁の数字に対して
- 検索
- (\d{1,1})
- 置換
- <span class="tcy">$1</span>
2桁の数字に対して
- 検索
- (\d{2,2})
- 置換
- <span class="tcy">$1</span>
3桁の数字に対して
- 検索
- (\d{1,1})(\d{1,1})(\d{1,1})
- 置換
- <span class="tcy">$1</span><span class="tcy">$2</span><span class="tcy">$3</span>
4桁の数字に対して
- 検索
- (\d{1,1})(\d{1,1})(\d{1,1})(\d{1,1})
- 置換
- <span class="tcy">$1</span><span class="tcy">$2</span><span class="tcy">$3</span><span class="tcy">$4</span>
miの場合
1桁の数字に対して
- 検索
- \b([0-9])\b
- 置換
- <span class="tcy">$1</span>
2桁の数字に対して
- 検索
- \b([0-9][0-9])(?!\d)
- 置換
- <span class="tcy">$1</span>
3桁の数字に対して
- 検索
- \b([0-9])([0-9])([0-9])(?!\d)
- 置換
- <span class="tcy">$1</span><span class="tcy">$2</span><span class="tcy">$3</span>
4桁の数字に対して
- 検索
- \b([0-9])([0-9])([0-9])([0-9])(?!\d)
- 置換
- <span class="tcy">$1</span><span class="tcy">$2</span><span class="tcy">$3</span><span class="tcy">$4</span>
5桁以上の数字については、3桁→4桁の法則に沿っていけばOKです。
タグ付けが終わるとこんな感じになります。

ちょっとわかりづらいですが…。
ルビダグ
「ルビ」とは読みづらい文字に振られる“ふりがな”のことを指します。

上のようにルビを振るには、下記の通りにタグをつけます。
増大に<ruby>拍車<rt>はくしゃ</rt></ruby>をかけています。
構成はちょっと分かりにくいかもしれませんが
<ruby>と</ruby>のタグの間に「漢字+よみがな」の順で並べ、さらに「よみがな」を<rt>と</rt>で挟む。
となっています。
それでは正規表現を使い、ルビタグを付けていきましょう。ルビタグを振るのに使用する正規表現は下記の通りです。(青空文庫原稿用です)
似たような検索置換を2回掛けます。
一回目
二回目
もし青空文庫以外の原稿にルビタグをつける場合、原稿自体を青空文庫と同じ体裁(漢字+《ふりがな》)にして上記の正規表現を使うか、もしくは別の正規表現を考えるか、のいずれかの対応になると思います。
今日のまとめ
正規表現を利用したタグ付け作業
付けたタグの種類
- pタグ(本文段落タグ)
- hタグ(見出しタグ)
- 縦中横タグ
- ルビタグ
次回は
電子書籍づくり実践(表示の確認。その方法)ついてお話します。